Efficient Statistical-Based Gradient Compression Technique
Increasingly complex DNN models and ever larger datasets are shifting ML training workloads to powerful clusters of GPU-enable workers that are used to parallelize the training process. In the prominent case, distributed workers operate in a data-parallel fashion with each worker processing a shard of the data, processing data in mini-batches and communicating after every mini-batch iteration to exchange gradients with other workers.
The time to fully train a model thus depends on the performance of the gradient communication phase, which for very complex/large models is a major performance bottleneck. Even more so, when training is distributed over the wide-area network such as across different datacenters or data silos. Recently, compression techniques were proposed to speed up this communication phase. Our GRACE project surveyed and evaluated many such techniques. However, compression becomes a significant overhead on the training process, especially for slow and inefficient compressors.
We advocate in this project for a highly efficient compression method. Specifically, we propose an efficient gradient compression technique called SIDCo. Several works tried to speed-up TopK compression by estimating, from the gradient vector, a threshold to filter out the TopK elements. However, these works suffered from inefficient methods or poor threshold estimation quality, which lowers training performance in terms of time and accuracy. SIDCo uses a statistical-based approach to fit the gradient. To do so, it leverages Sparsity-Inducing Distributions (SIDs) and Mutli-Stage Threshold Refinement. The figure below illustrates the high-level design of SIDCo as part of the distributed training pipeline.
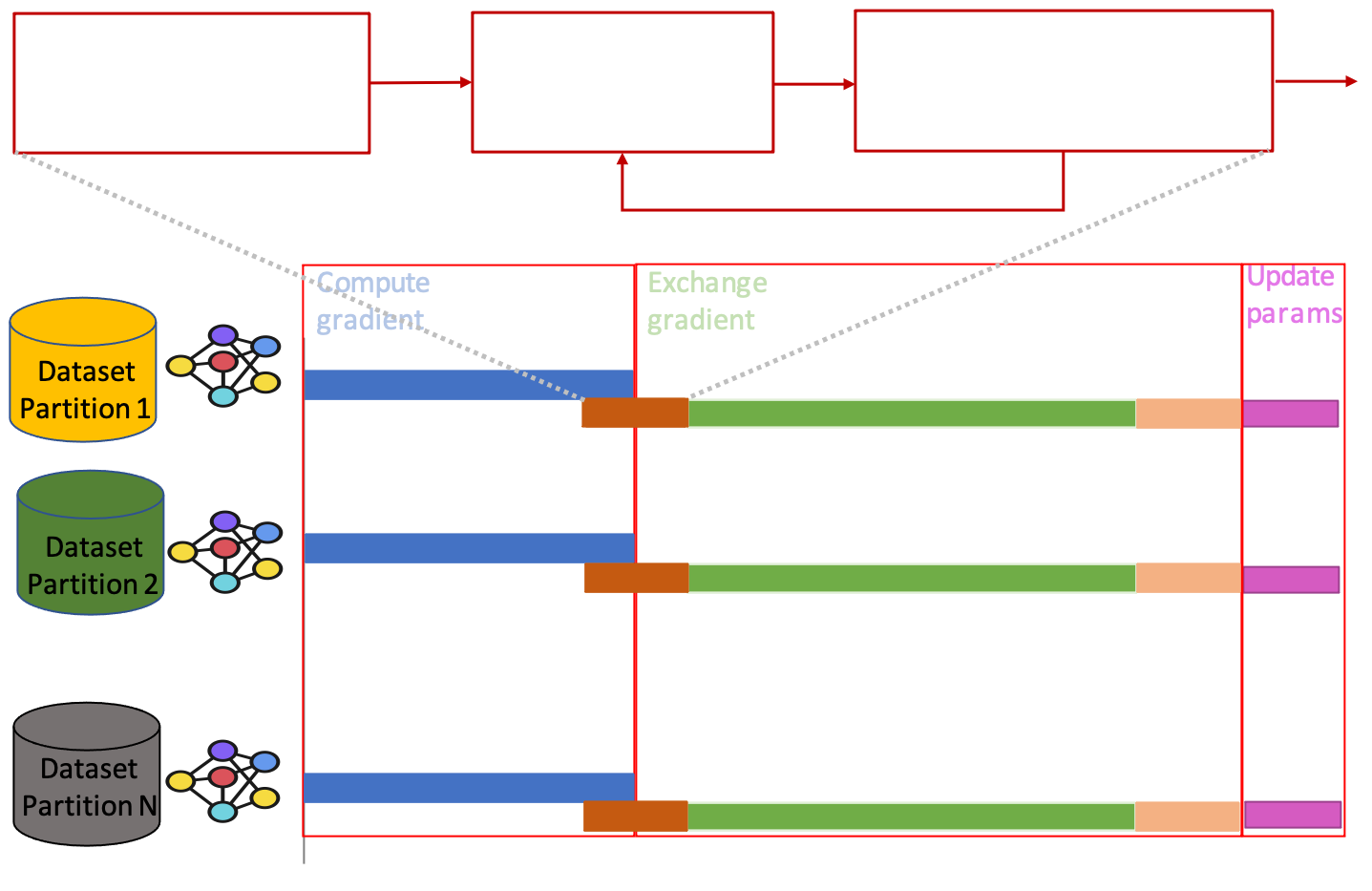
SIDCo achieves high efficiency and accelerates distributed training systems thanks to its low-overhead computations for the threshold and the high accuracy of the estimated threshold. SIDCo is implemented as a drop-in compression module which is added to the communication library of distributed ML frameworks (e.g., Horovod).
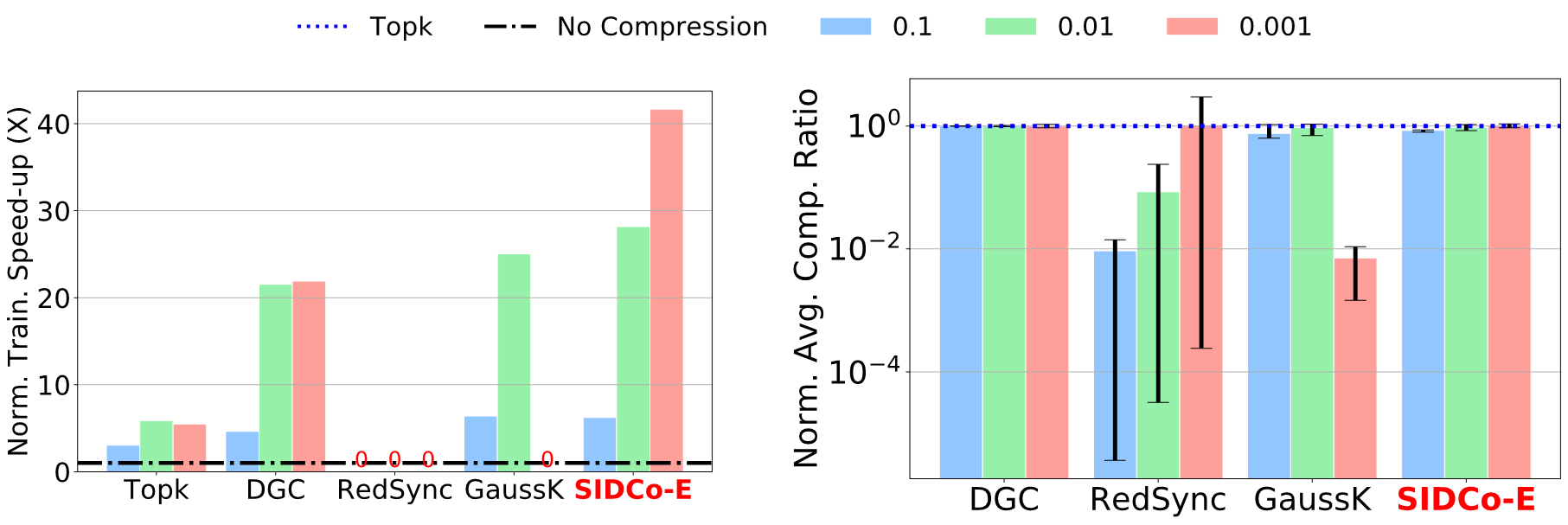
We empirically evaluated SIDCo against state-of-the-art compression methods in several DNN benchmarks spanning tasks of image classification, next word prediction, and speech recognition. The figure below shows the speed-up and estimation quality results of training RNN-LSTM model on the PTB dataset. The plot on the left shows that SIDCo-E (using Exponetial SID) accelerates the training by up to 41× over a baseline with no compression and achieves up to 2× higher speed-up than DGC, a state-of-the-art compressor. The plot on the right shows that SIDCo achieves the best estimation quality (i.e., normalized average compression ratio) compared to other threshold-estimation compressors, RedSync and GaussianKSGD.