Delay-aware Communication Control for Distributed ML
Increasingly complex DNN models and ever larger datasets are shifting ML training workloads to powerful clusters of GPU-enable workers that are used to parallelize the training process. In the prominent case, distributed workers operate in a data-parallel fashion with each worker processing a shard of the data, processing data in mini-batches and communicating after every mini-batch iteration to exchange gradients with other workers.
The time to fully train a model thus depends on the performance of the gradient communication phase, which for very complex/large models is a major performance bottleneck. Even more so, when training is distributed over the wide-area network such as across different datacenters or data silos. Recently, compression techniques were proposed to speed up this communication phase. Our GRACE project surveyed and evaluated many such techniques. However, compression comes at the cost of reduced model accuracy, especially when compression is applied arbitrarily.
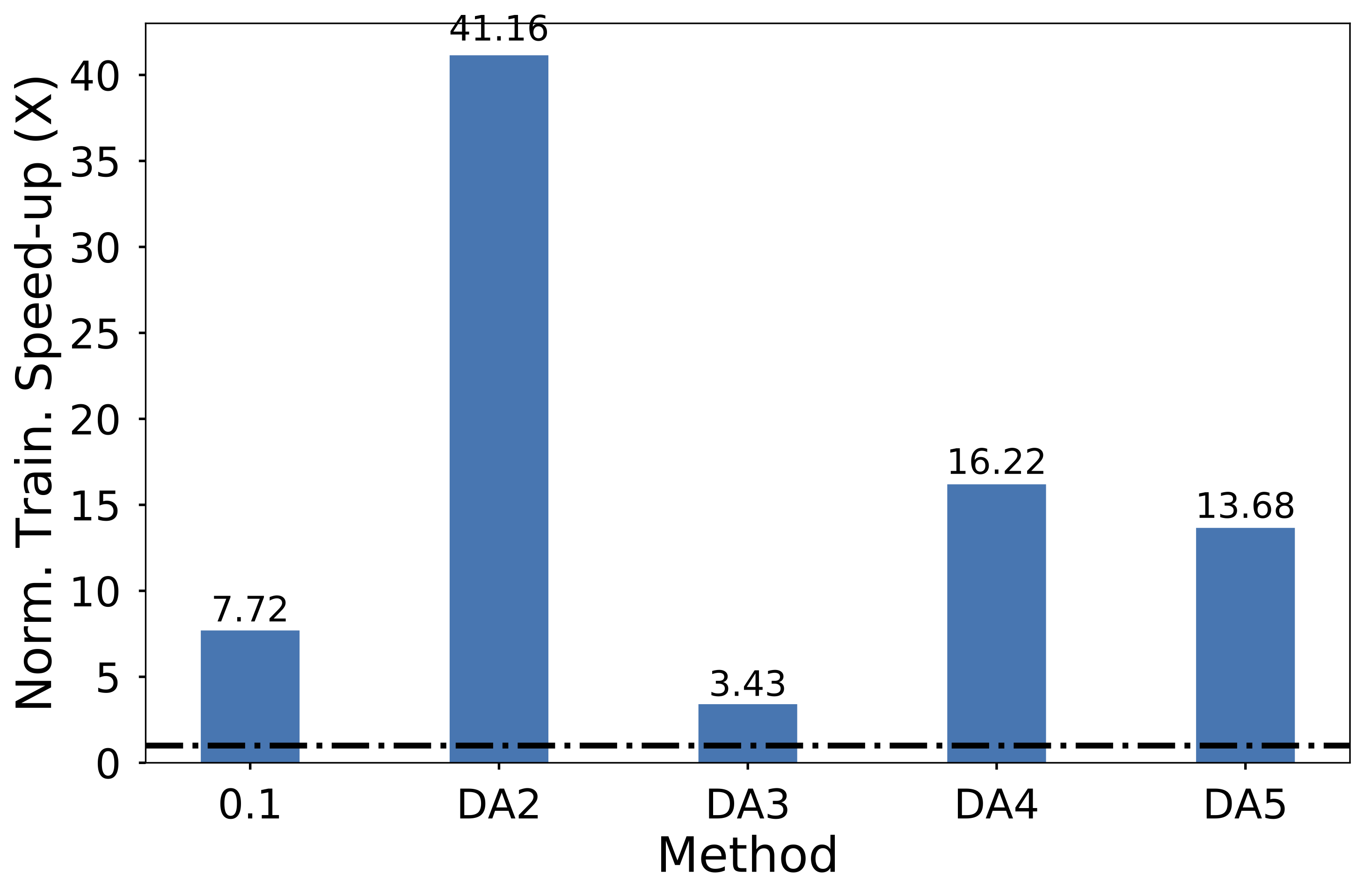
We advocate in this project for a controlled use of compression. Specifically, we propose a delay-aware compression control mechanism called DC2. Unlike existing works that apply compression blindly regardless of variable network conditions, DC2 couples compression control and communication delay to apply compression adaptively. The figure below illustrates how DC2 controls the compression in response to changes in the network dynamics.
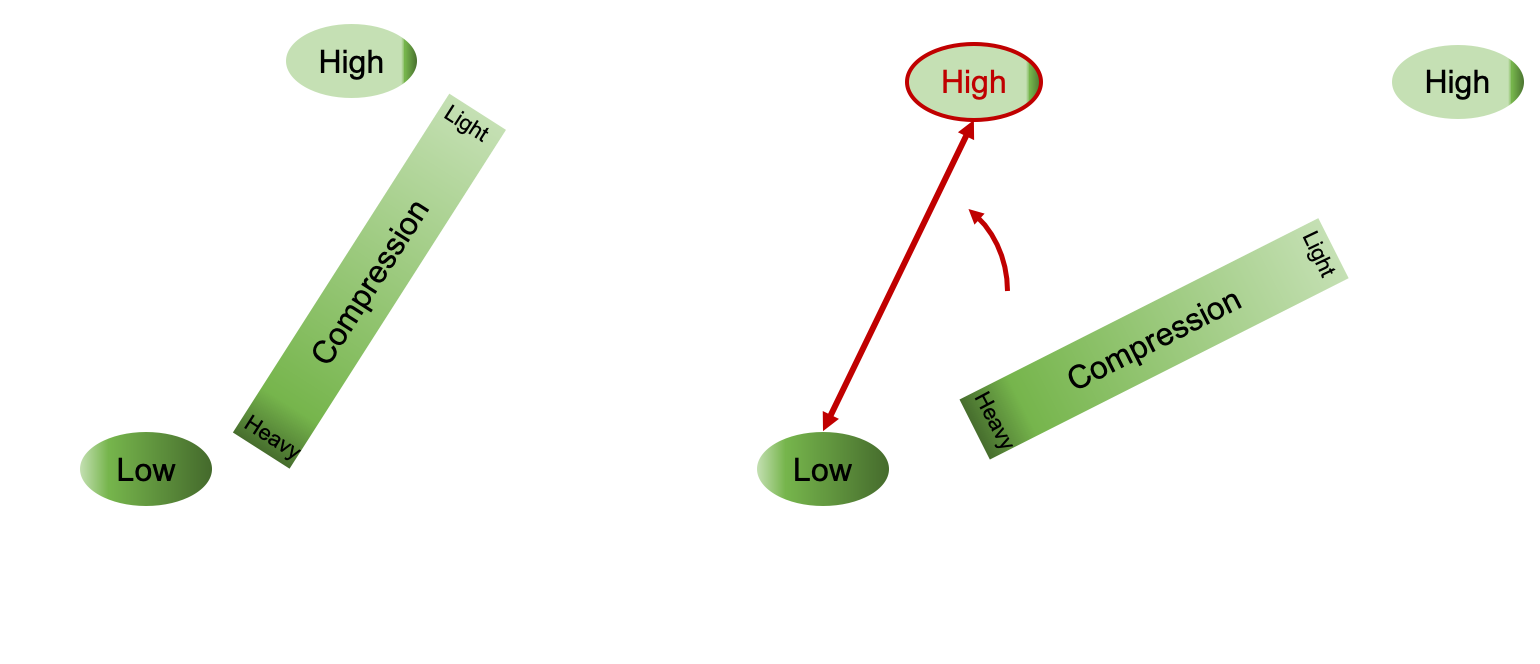
DC2 not only compensates for network variations but can also strike a better trade-off between training speed and accuracy. DC2 is implemented as a drop-in module to the communication library of distributed ML frameworks (e.g., Horovod) and can operate in a variety of network settings. As shown in the figure below, the system is implemented as an application-level monitor and control modules. The monitor module constantly monitors the network conditions and feeds the collected network statistics into the control module. The control module uses the network statistics and applies control logic inspired by congestion control protocols to adapt the level of compression in response to the network dynamics.
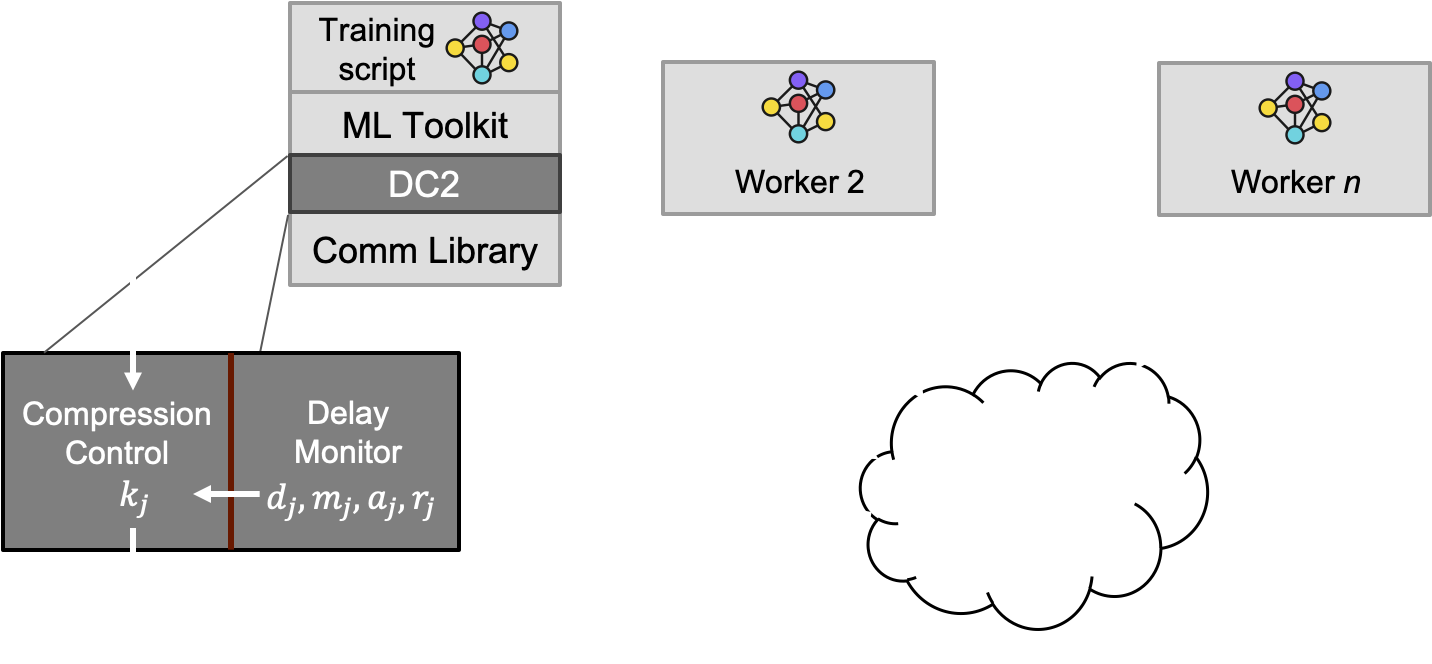
We empirically evaluated DC2 in network environments exhibiting low and high communication delay variations. Our evaluation includes a wide range of popular CNN and RNN models and datasets. The figure below shows the speed-up results of training RNN-LSTM model on the PTB dataset. It shows that various DC2 control methods (called DA*) improve accelerate training by up to 41X over a baseline with no compression and achieve are up to 5.3 times faster than schemes that apply a fixed level of compression.