Scaling Distributed Machine Learning with In-Network Aggregation
SwitchML is a system for distributed machine learning that accelerates data-parallel training using P4 switches. SwitchML uses in-network aggregation to reduce data transfer during synchronization phases of training. By co-designing the software networking end-host stack and the switch pipeline, SwitchML greatly reduces the volume of exchanged data and the latency of all-to-all communication, speeding up training 8 industry-standard DNN benchmarks by up to 5.55×.
Distributed machine learning (ML) has become common practice, given the increasing complexity of Deep Neural Network (DNN) models and the sheer size of real-world datasets. While GPUs and other accelerators have massively increased compute power, networks have not improved at the same pace. As a result, in large deployments with several parallel workers, distributed ML training is increasingly network bounded.
The network bottleneck for training workloads arises from the need to periodically distribute model updates in order to synchronize workers. This communication is usually done with collective operations (i.e., all-reduce) or enabled by parameter servers. Both require many CPU cycles to aggregate updates and are oblivious to the physical network topology. SwitchML co-designs the switch processing logic, end-host protocols, and ML frameworks to offload aggregation directly to switches. This reduces the amount of data transmitted during synchronization phases, speeding up training time.
In this project, we address three main problems with using programmable switches in such a fashion: limited computational power, maintaining synchronization, and dealing with failures. We address these challenges by appropriately dividing the functionality between hosts and switches, resulting in an efficient and reliable streaming aggregation protocol. Our technical report linked below desribes this in detail.
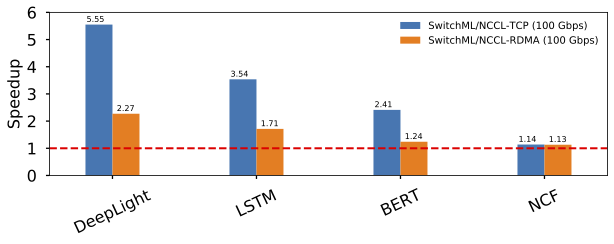
We analyze the performance of SwitchML using standard benchmarks on popular DNNs in PyTorch and TensorFlow. The figure below shows the training performance speedup compared to using the NCCL library with a 100 Gbps network. Overall, SwitchML accelerates training by up to 5.55×. As expected, different models benefit from in-network aggregation differently, depending on how network-bound they are.
This project is a collaboration with colleagues at Microsoft Research, University of Washington and the Barefoot Networks division at Intel. We are grateful to Intel for hardware donations and Huawei for a in-kind gift to support this research.