Efficient collective communication is crucial to parallel-computing applications such as distributed training of large-scale recommendation systems and natural language processing models. We propose OmniReduce, an efficient streaming aggregation system that exploits sparsity to maximize effective bandwidth use by sending only non-zero data blocks. We demonstrate that this idea is beneficial and accelerates distributed training by up to 8.2×.
Efficient Sparse Collective Communication
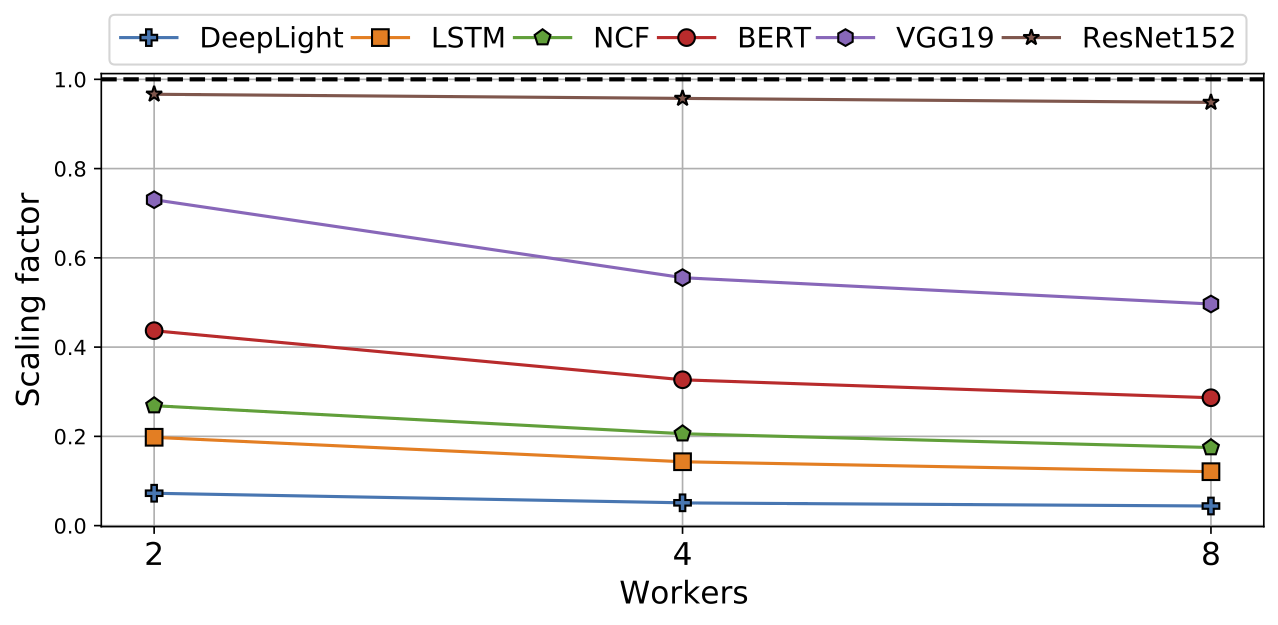
Existing collective communication libraries such as NCCL or Gloo focus on optimizing operations for dense inputs, resulting in transmissions of many zeros when inputs are sparse. This counters current trends that see increasing data sparsity in large DNN models. Moreover, this causes significant communication overheads during distributed training. The figure below shows that these overheads are substantial in many DNN workloads, especially for large models where there exists a significant gap between the measured performance and ideal linear scaling (represented as a factor of 1 in the figure).
The goal of this project is to design efficient collective operations for sparse data. OmniReduce is a streaming aggregation system designed to maximize the efficient use of bandwidth, and serve as a drop-in replacement for the traditional collective libraries. OmniReduce exploits the sparsity of input data to reduce the amount of communication. Key to OmniReduce’s efficiency is an aggregator component that determines the non-zero data at each worker in a streaming look-ahead fashion. OmniReduce splits input data into blocks where a block is either a split of contiguous values within an input vector in a dense format or a list of key-value pairs representing non-zero values. OmniReduce achieves high performance through fine-grained parallelization across blocks and pipelining to saturate network bandwidth. OmniReduce leverages fine-grained control of the network to design a self-clocked, bandwidth-optimal protocol and an application-aware failure recovery mechanism to recover from packet losses. The block-oriented approach, fine-grained parallelism and built-in flow control afford us the opportunity to implement the aggregator in-network using modern programmable switching ASICs.
Accelerate Distributed Deep Learning with OmniReduce
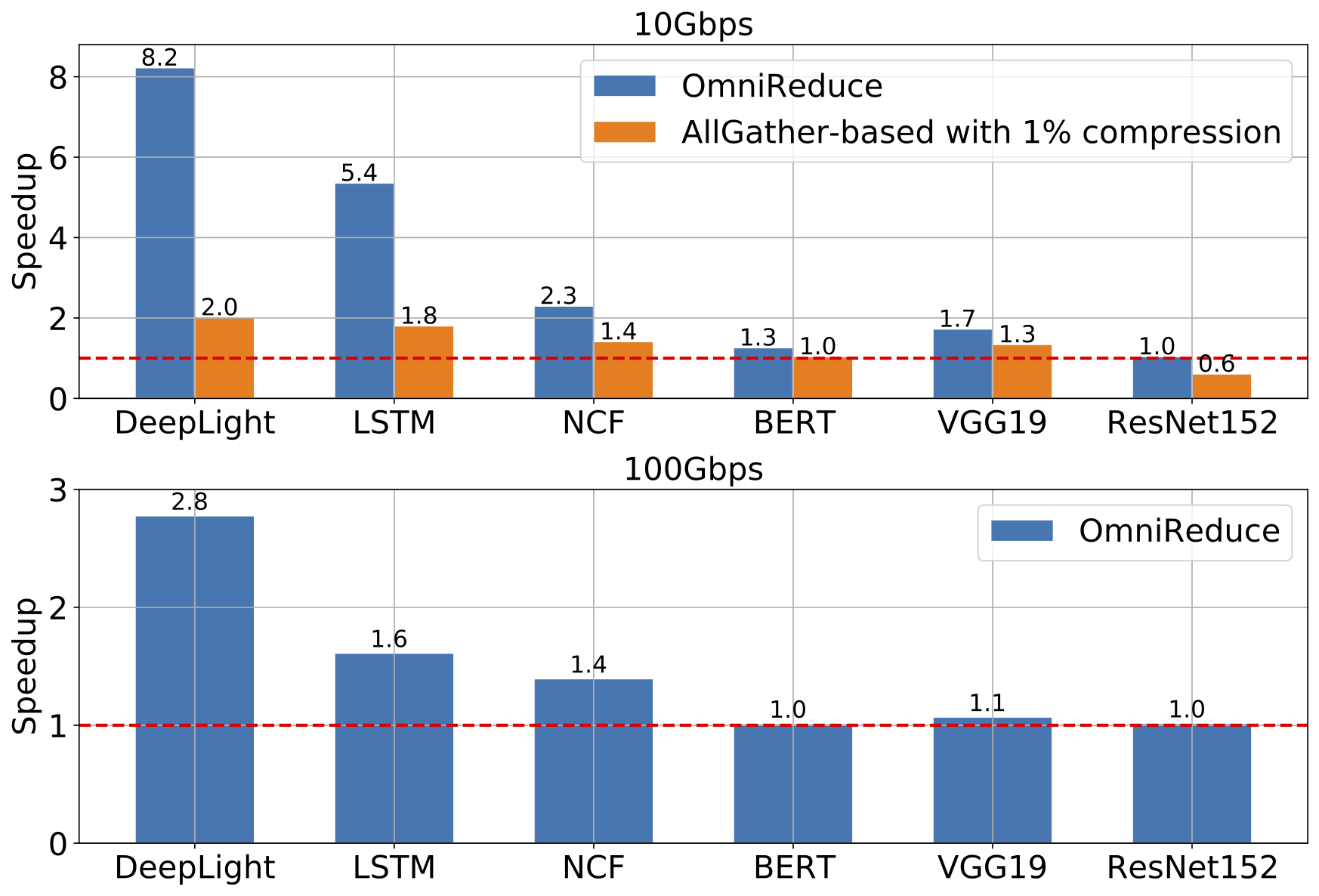
We quantify the performance benefits of OmniReduce using six popular DNN workloads. In end-to-end settings, OmniReduce speeds up training throughput by up to 8.2× at 10 Gbps, 2.9× at 100 Gbps compared to NCCL (which treats inputs as dense). OmniReduce is also effective for large-DNN distributed training jobs with multi-GPU servers.
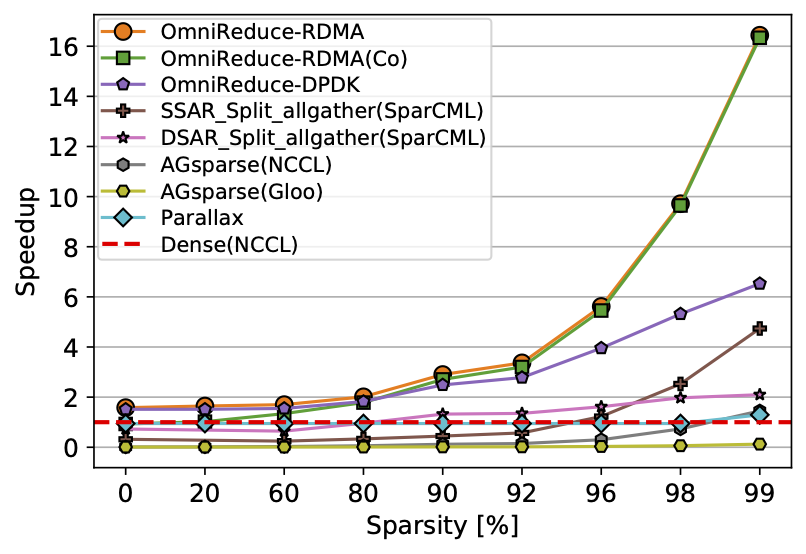
We also use benchmarks to compare to state-of-the-art sparse collective solutions in both TCP/IP and RDMA networks. We compare against (1) AllGather-based sparse AllReduce (AGsparse), as implemented by PyTorch; (2) SparCML collectives for arbitrary sparse input data designed for DDL; and (3) Parallax, a hybrid system that uses a parmater server for sparse data and AllReduce for denser data. Our results show that OmniReduce outperforms these approaches by 3.5–16×.